Typing Bangla TeX/LaTeX Source (bangtex)
Directly in Native Bangla (Unicode/UTF-8)
Introduction
bangtex: Bangla TeX and LaTeX
For typesetting Bangla documents in TeX/LaTeX,
Palash B. Pal's excellent
bangtex package is the best.
bangtex uses a particular ASCII transliteration
of Bangla (a specific orthographically accurate romanization of Bangla),
which also has a few mechanisms for better readability
(such as the \*...* construct and the superfluous use
of the letter o).
The seicor script can further improve
readability of the source.
The Problem
Can we avoid romanization in typing LaTeX source in Bangla?
As a native Bangla user used to exchanging Bangla emails and writing
Bangla webpages in html text, I find it very convenient to
type text directly in Bangla into text editors which display
the typed text in native Bangla symbols and
use the now-standard (and essential) font-independent unicode UTF-8
character encoding (instead of any romanized form) for text storage.
So for me, it seemed painful to learn a specific romanized form
(ASCII transliteration) of written Bangla for typing LaTeX source documents.
Could I somehow
write TeX/LaTex source files directly in Bangla and
still use bangtex?
The Solution:
Use This Script to Convert Bangla Unicode into
bangtex's Transliterated ASCII Format
Typing LaTeX source documents
directly in unicode Bangla
A simple solution was to prepare the LaTeX source document using
unicode UTF-8 encoded Bangla text,
and then use a special script called
uni2bangtex.perl
to convert it into transliterated ASCII in
bangtex format.
Since unicode UTF-8 encoding is a superset of ASCII,
the ASCII needed to type the LaTeX commands
can be freely mixed within the UTF-8 Bangla source text.
This means that I can use any unicode UTF-8 editor to prepare
the LaTeX source directly in Bangla, with any appropriate
Bangla keyboard input method (phonetic, inscript, etc) and
any Bangla font for UTF-8 (usually truetype or opentype)
--- see the screenshot below.
If your native language is Bangla, you will probably find
this to be a faster, more pleasant, more intutive,
and less error-prone way to type the source LaTeX document
than using a specific romanized form (ASCII transliteration) of Bangla.
An Example
Preparing a sample LaTeX Bangla document
Let us go through an example showing how to prepare
a sample Bangla LaTeX document named
smpldoc:
- Step 1 :
Prepare the LaTeX source document in unicode UTF-8 Bangla text.
Here is a screenshot showing the unicode Bangla LaTeX source text file
smpldoc.txt
being prepared in the editing window of a unicode editor
called yudit using the SolaimanLipi font
(you can of course use any unicode UTF-8 editor and Bangla font
of your choice).
The source being prepared in a UTF-8 text editor
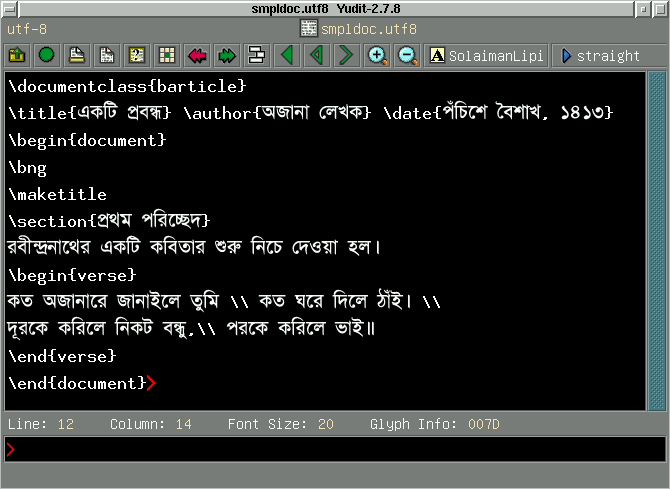
|
The editing session displayed above was run by the command
yudit smpldoc.txt
where the LaTeX source document
smpldoc.txt
is the unicode UTF-8 encoded Bangla text file.
In the above screenshot you can see that
LaTeX commands in ASCII are mixed freely with Bangla characters,
a nice feature of the UTF-8 encoding.
- Step 2 : Convert the Bangla unicode into
bangtex format ASCII transliteration.
To convert smpldoc.txt (which is a unicode text file)
into bangtex format ASCII transliteration,
run the following command:
uni2bangtex.perl smpldoc.txt > smpldoc.tex
The perl script
uni2bangtex.perl
parses the unicode UTF-8 encoded Bangla source document,
and converts it into transliterated ASCII in bangtex format.
(Thus, like seicor, it is
a supporting tool for the bangtex package.)
The resulting file smpldoc.tex
is a pure ASCII bangtex format LaTeX file with the following contents:
\documentclass{barticle}
\title{EkiT pRbn/dh} \author{Ajana elkhk} \date{pNNicesh {oi}bshakh, 1413}
\begin{document}
\bng
\maketitle
\section{pRthm pirec/chd}
rbiin/dRnaethr EkiT kibtar shuru inec ed{O}ya Hl.
\begin{verse}
kt Ajanaer jana{I}el tuim \\ kt gher idel ThNNa{I}. \\
duurek kirel inkT bn/dhu,\\ prek kirel bha{I}..
\end{verse}
\end{document}
|
However, I never need to directly view or edit this file, and
regard it as an "intermediate machine file".
- Step 3 : Run latex/pdflatex as usual.
Finally, run pdflatex (or latex) as usual on the
intermediate machine file (the pure ASCII
bangtex format LaTeX file)
smpldoc.tex:
pdflatex smpldoc.tex
This produces the final PDF output
smpldoc.pdf
which looks like:
The final PDF produced by pdflatex
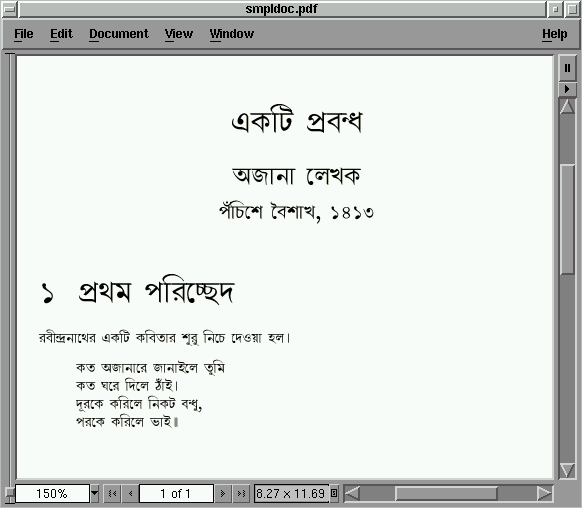
|
System Requirements
What you need on your computer
For a setup like the one I have described above,
you will need to have the following installed on your computer:
-
The
bangtex package, and the bpsf font package.
-
Perl version 5.8.5 or newer, and the script
uni2bangtex.perl.
The script will not work with old versions of Perl with broken
unicode UTF-8 support.
-
A UTF-8 Bangla text editing setup,
which may very well be present already in your system,
as recent versions of most modern operating systems with
graphical desktops have UTF-8 based multilingual support.
This means any unicode UTF-8 editor, supplied with a font capable of
displaying Bangla and a unicode Bangla keyboard input method
of your choice (e.g., a phonetic layout such as
Probhat).
If you are not familiar with this,
see the Appendix below for more details.
Download
The perl script file and this webpage
Download the perl script
uni2bangtex.perl.
The script needs perl-5.8.5 or newer.
You can also download a complete tarball
of this webpage, with all the sample files and images in it.
About unicode and UTF-8
What is unicode and UTF-8?
Unicode
is a standard for font-independent and orthographically accurate
digital representation of written language using character codes.
The role unicode plays for general
languages is identical to the role played by the ASCII code for English.
In particular, there is a perfect one-to-one correspondence
between Bangla unicode and written Bangla which preserves all spellings.
In this way, unicode can be viewed as an extension of ASCII to
encode the characters of all other languages. In fact, a specific unicode
encoding scheme called UTF-8
is designed in such a way that it is a direct
superset of ASCII. Thus a UTF-8 text document can contain ASCII characters,
and an ASCII text document is simply a special type of UTF-8 text document.
To learn more,
see the UTF-8 and Unicode FAQ for Unix/Linux.
On recent linux systems, you can look up the manpages for
unicode(7), utf-8(7), and charsets(7).
Why use unicode for encoding Bangla text in this way?
We note the following points in support of unicode for encoding Bangla text.
-
We repeat:
The role of unicode UTF-8 for encoding Bangla text
(and most other languages) is identical to
that of ASCII for encoding English text:
Unicode provides a standardized, font-independent, and
orthographically accurate representation
of written language for essentially all languages,
making it perfect for digital storage and communication of
"pure text" documents.
In particular,
it is as easy and convenient to use a unicode text editor
to write Bangla web pages in direct html text
or to compose and send text emails
in Bangla, as it is to do these things in English. (ASCII had been providing
this functionality only for English and a few languages
based on the Roman character set.)
-
Use of unicode (especially UTF-8) in Bangla documents is now widespread.
Websites like the
Bangla Wikipedia,
the Bangla version of Google's search engine,
news media such as
Bangla BBC,
Bangla Deutsche Welle,
and
Bangla China Radio International
--- all use UTF-8 encoded Bangla web pages as their standard.
Notably, the entire
Rabindra Rachanabali
is now on the web thanks to SNLTR, and they plan to add more classic
Bangla literature.
-
UTF-8 has the remarkable property that written texts of multiple languages
(ASCII, Bangla, and most other languages) can be freely mixed in the same
text document (while being font independent) and can then be easily
separated back again (because different languges have disjoint sets
of character codes). This makes it
useful not only for TeX/LaTeX, but also for most markup languages (such as xml),
and vitally for html. It has been
reported
that the vast majority of webpages now use UTF-8.
- For bangtex, using unicode for the source text file
makes its character encoding standardized, and so
the source text file becomes portable for sharing,
i.e. readable and usable by most users of Bangla computing
such as Bangla magazine editors, even if they are
not familiar with TeX/LaTeX (the embedded Tex/LaTeX
formatting commands in ASCII does not affect the content too much,
and are often self-explanatory).
Even for Tex/LaTeX users, this provides much better readability
of the source text file, since (a) there is no more
romanization (transliteration of Bangla into ASCII),
and (b) the user can freely choose the (opentype/truetype)
Bangla text font for viewing the source text.
-
UTF-8 encoded pure Bangla text can now be quickly turned into
a TeX/LaTeX source text by inserting some TeX/LaTeX formatting commands
into the UTF-8 encoded text itself, without having to
first manually convert it into transliterated ASCII in bangtex format
(the conversion being done by the script).
-
Unicode also makes the "cut and paste" feature of character based documents
highly portable.
As more and more Bangla references are becoming available on the web,
this makes it easy to quote from them
in documents. Recently, I needed to quote a large section of an
article of Rabindranath into a Bangla article composed in bangtex.
I went to the online version of that article on the
Rabindra Rachanabali website,
and then simply did a "cut and paste" of the relevant section
into my bangtex article. (Without the uni2bangtex script,
I would have to manually transliterate the quoted section into
romanized bangtex form, spending considerably more time
in "data entry".)
-
Using unicode allows the user to customize the keyboard
input method. Users familiar in typing with the romanized
QWERTY keyboard will probably prefer Bangla phonetic keyboard layouts
such as Probhat or Baishakhi (as opposed to non-phonetic layouts
such as Inscript or Unijoy). Even further customization,
including modification of the phonetic transliteration mapping
for the keyboard, is possible.
-
Using a unicode text editor to compose the source document can be
somewhat less error prone and more pleasant for native Bangla users
than using a romanized transliteration of Bangla, since the
instant rendering of written Bangla directly into
a Bangla font constantly provides the same visual feedback loop
as the one used when reading or writing native language on paper.
Appendix
Setting up Bangla unicode text support in Linux / X windows
You need three things for using Bangla unicode text on Linux:
- A text editor with UTF-8 support.
(This means a simple character based text editor,
not a word processor such as OpenOffice or MS word.)
This may already be present in your system, as
most modern operating systems with graphical desktops
have a default GUI editor with this feature.
For example, many Linux distributions include
either GNOME's default text editor gedit or KDE's
default text editors Kate and/or Kwrite, MS Windows
comes with Notepad, Mac OS X has TextEdit, etc,
and all these now support multilingual UTF-8.
If your system does not have it, you may want to
install and use the simple free classic UTF-8 editor
yudit.
Other choices are possible, such as the GNU super-editor Emacs.
See
Wikipedia's Comparison of text editors.
- To display Bangla text, the editor will need a
font capable of rendering unicode UTF-8 Bangla.
This will usually be an opentype or truetype font.
Note that this font is only for displaying Bangla in the
text editor in which you prepare the LaTeX source document,
and has nothing to do with the font of the final document
output by bangtex (such as bpsf).
Again, most modern operating systems now come with default fonts
for displaying most of unicode UTF-8, and so it may not be necessary
to install any special Bangla UTF-8 font, unless you do not like
the system default fonts for displaying Bangla.
See Bangla script display help at
Wikipedia and
Bangla Wiktionary for more details.
If you need to install Bangla fonts:
- A keyboard input method for typing Bangla UTF-8
characters using a romanized keyboard
(usually QWERTY).
Once again, most modern operating systems provide keyboard layouts
for various languages and a way to switch between various layouts.
The default layout usually is a form of English, which maps
keyboard scan codes into ASCII characters. Switching to a
different layout will cause this map to change, and a Bangla
layout will map keyboard scan codes into Bangla UTF-8
characters instead of ASCII characters.
See Bangla script input help at
Wikipedia and
Bangla Wiktionary for more details.
There are different types of layouts for Bangla available,
such as phonetic, non-phonetic, etc.
If you are used to typing on QWERTY keyboards using primarily
a language with essentially Roman script (English, German, French,
Spanish, Italian, etc) and you are new to Bangla typing,
then you will probably find a phonetic layout to be
the easiest to use. For an X-window based system, a Bangla
phonetic layout called
probhat
(picture of layout) is generally available. I personally use a variant of it,
which I call suprobhat. Another possibility for a modern
phonetic layout is baisakhi (PDF document, picture of layout), developed by SNLTR.
Also see
this explanation of phonetic Bangla typing.
Low Level Keyboard Layout Switching in X windows
Warning!
You should not use this method unless you really know what you are doing,
or else it can make your computer unusable.
If you use a modern distribution of Linux with a graphical desktop manager
such as GNOME or KDE, you will most likely have a way (perhaps
a menu in your desktop manager or a graphical applet)
to switch your keyboard layout, and you should use it
to select a Bangla layout of your choice (e.g., Probhat).
If you really want to use this low level method (bypassing your
desktop manager) to switch to a new keyboard layout,
use the setxkbmap command to directly
instruct the X windows server to select or switch to an
xkb keyboard layout for X, which are found
in the directory /etc/X11/xkb/symbols/.
Look there for a file named in (for India),
or bd (for BanglaDesh), or ben or bang,
which should have an entry for the Probhat layout, named
ben_probhat, or simply probhat.
(You can also download the layout here.
I personally use a variant of probhat which I call
suprobhat.)
E.g., if the file /etc/X11/xkb/symbols/in has a layout entry called ben_probhat,
you can activate it by a command such as
setxkbmap -model pc101 -layout "us,in(ben_probhat)" -option "grp:shifts_toggle,grp_led:num"
or
setxkbmap -model pc101 -layout "us,in(ben_probhat)" -option "grp:shift_toggle,grp_led:num"
depending on the version of your X. This will set things up in xkb
so that pressing the two shift keys together will toggle between the
standard US (English) and the ben_probhat (Bangla) keyboard layouts.
Web Resources
Abhijit Dasgupta
Thu Oct 7 03:11:55 EDT 2010
{kind=link}
{kind=link}